소나큐브 파이프라인 구축 (1) 로컬 - 설치
코드 품질 향상 및 보안 강화를 목적으로 팀내에서 정적 분석 툴을 도입하기로 했다. 소나큐브 서버를 설치해서 정적 검사를 진행하기로 했고, 적용하기 전에 로컬에서 먼저 테스트를 진행했다.
로컬에 깃랩 서버를 도커로 올리고 Jenkins 서버와 Sonarqube 서버는 운영체제 위에 세팅했다. 모두 다 도커로 올리는 것이 설정하는데 좀 더 편했을 것 같다.(모두 다 윈도우에 올리거나) 도커에서 로컬 서버와 통신을 위한 네트워크 설정, 도커 서버에서 사용하는 데이터 영속화를 위한 디렉토리 설정 등 따로 해줘야 할 것들이 있어서 불편했다. 테스트 환경을 구축할 때는 편한대로 하는 것보다 먼저 배포해야 할 환경을 분석하고 이에 맞게 테스트 환경을 구축하는 것이 가장 올바른 테스트 환경 구축인 것 같다. 이렇게 테스트하고 배포하는 것이 실제로 배포할 때도 훨씬 편하고 안정적이다.
로컬 구성도
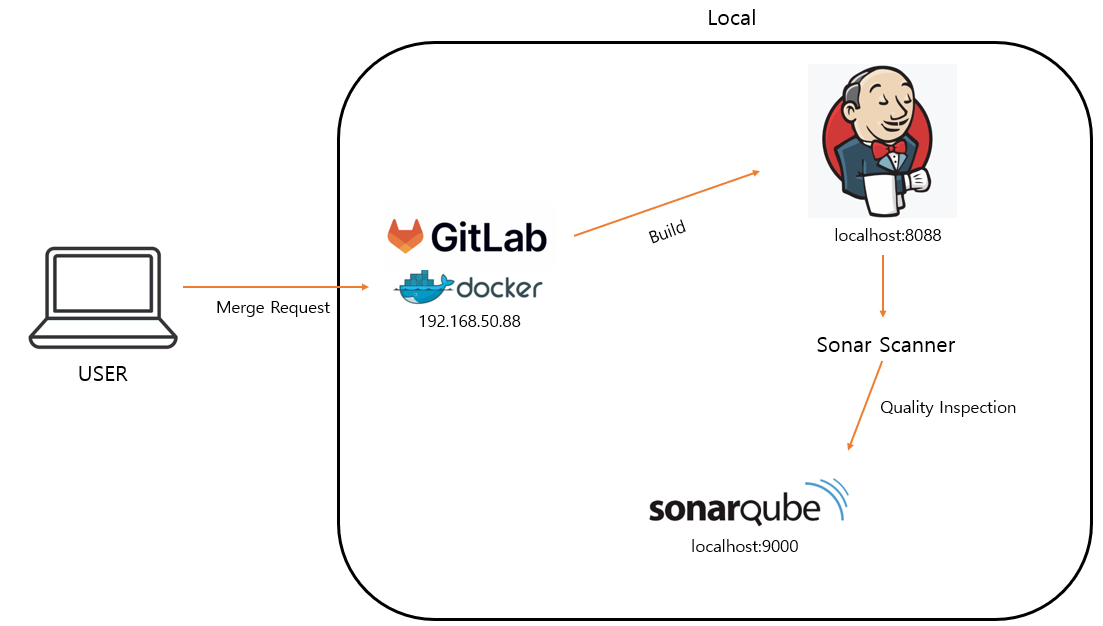
언제 검사하느냐를 결정해야했다. 원칙대로 하면 MR발생 → 정적 분석 → 결과에 따라 병합 여부 결정 과정으로 진행해야했다. 원칙대로하면 좋겠지만, 팀 내 개발 특성상 빠르게 개발을 진행해야 할 때가 있어서 MR 발생 시 분석만 진행하고 결과에 상관없이 병합을 진행되도록 설정했다.
큰 흐름은 아래와 같이 생각했다.
MR 발생
깃랩 → 젠킨스 webhook 전달
Jenkins 파이프라인
SonarQube 정적 분석
Jenkins에서 결과 확인
정적 분석 파이프 라인은 현재 프로젝트에서만 사용하지 않고 나중에 다른 프로젝트에서도 재사용할 수 공통 라이브러리로 사용할 수 있도록 설계했다.
소나큐브 호출 부분은 따로 라이브러리를 만들고 프로젝트마다 프로젝트에 맞는 파라미터를 공통 라이브러리로 전달해 검사가 진행되도록 전체 구조를 생각하며 테스트를 진행했다.
1. 소나큐브
설치 시 크게 두 가지 초기 설정을 해야했다.
데이터베이스
메모리 설정
1-1 데이터베이스
소나큐브는 분석 결과를 기본적으로 H2DB에 저장한다. H2DB는 빠르게 개발할 때는 유용하지만 데이터 안정성과 동시 처리 능력이 낮기 때문에 개발이나 운영 환경에는 적절하지 않다.
소나큐브에서도 H2DB를 그대로 사용하지말고 postgres를 사용할 것을 권고한다. 로컬에서는 H2DB를 사용해서 테스트를 진행했다.
1-2 메모리 설정
소나큐브는 내부 검색 시스템으로 엘라스틱 서치를 사용한다. 처음 서버를 구동할 때 엘라스틱 서치 메모리 관련해서 오류가 많이 발생했다. 엘라스틱 서처 메모리 설정과 소나큐브 자체의 메모리 설정을 진행했다.
# /opt/sonarqube/conf/sonar.properties
sonar.search.javaOpts=-Xms2g -Xmx2g# /opt/sonarqube/bin/linux-x86-64/sonar.sh
cd "`dirname \\"$REALPATH\\"`"
# Elasticsearch JVM 옵션 export
SONAR_SEARCH_JAVA_OPTS=$(grep '^sonar.search.javaOpts=' ../../conf/sonar.properties | cut -d= -f2-)
export SONAR_SEARCH_JAVA_OPTS
# 캐시 삭제 및 서버 재시작
sudo systemctl daemon-reexec
sudo systemctl restart sonarqube
💡Elasticsearch Launcher 프로세스
Launcher(Wrapped CLI)는
sonar-application.jar가내부적으로 Elasticsearch 실행을 위해 자바 런처 프로세스(Wrapper)를생성한다. 이 프로세스는CliToolLaucher클래스를 통해 진짜 Elasticsearch 실행부를 자식 프로세스로 fork 한다.이 프로세스는
Xmx64m으로 고정된다.이유는 Launcher는 단지 명령어 구성 및 실행용으로만 쓰이며, 메모리를 거의 사용하지 않는다.
Elasticsearch의실제 동작을 담당하지 않기 때문에 메모리를 늘리거나 하지 않아도 된다.
1-3 주요 구성
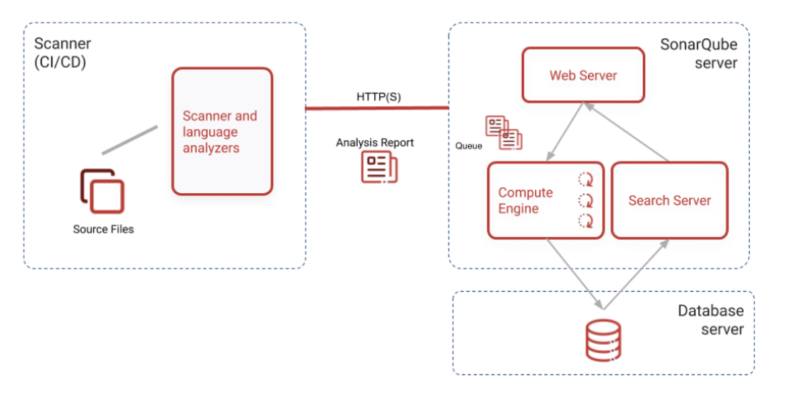
Sonar Scanner
정적 분석을 수행할 코드를 소나큐브 서버로 전달해주는 역할을 수행한다. 젠킨스에서 스캐너가 동작하게 될 구조다.
SonarQube server
정적분석을 수행할 프로그램이 실행되고 있는 서버이다.
스캐너로부터 API 요청을 받으면 해당 코드에 대한 정적 분석을 수행하고 리포트를 생성한다.
Database server
분석 결과를 영속화할 데이터베이스이다. (기본 H2DB)
2. GitLab
처음에는 클라우드 깃랩을 사용하려고 했다. 하지만 클라우드 깃랩을 사용하면 웹훅 기능을 쓸 수가 없어서 로컬에 설치해서 테스트를 진행했다. 깃랩 클라우드에서 웹훅 기능 자체를 지원 안 하기도 하고, 만약 지원하더라도 로컬로 받으려면 외부 라우터에서 포트포워딩을 해줘야 하는데 이건 권한밖이라 불가능한 방법이었다.
깃랩은 도커를 통해 올렸다. 도커와 운영체제의 서버와 통신하려면 네트워크 설정을 해줘야했다. 도커의 컨테이너들은 도커 내부의 IP로 통신하기 때문에 서로 바라보는 localhost가 다르다.
Docker 브리지 네트워크에서 호스트 접근이 가능하게 하는 설정 또는 Docker 컨테이너와 Jenkins를 같은 네트워크에 연결하는 방법 이렇게 두 가지 방안이 있었다. 간단하게 테스트를 하기 위해서 첫 번째 방법으로 진행했다.
# 도커 실행 시 아래와 같은 설정을 추가하면 "my-host"라는 별칭으로
# 도커에서 호스트의 서버에 접근할 수 있다.
--add-host=my-host:host-gateway3. Jenkins
젠킨스도 소나큐브와 마찬가지로 운영체제 위에 설치했다.
Jenkins에서 어떤 item을 생성할지 고민했었다. freestyle, pipeline, multibranch pipeline 중 어떤 item으로 생성하는 것이 가장 적합하거나 효율적일지 고민됐다.
Freestyle project 장단점
GUI를 통해 설정.
간단한 파이프라인 구축 시 용의함.
빠른 설정 가능
유연성 부족(병렬 처리, 조건부 실행 등 구현이 어려움.)
설정이 Jenkins 서버 내에만 저장되므로, 소스 코드와 함께 버전 관리가 어려움.
Pipeline 장단점
코드 기반으로 파이프라인 정의.
Jenkinsfile에 Groovy 언어를 사용하여 작성.
복잡한 파이프라인, 병렬 처리, 조건부 실행 등 다양한 시나리오 코드를 구현할 수 있음.
파이프라인 정의를 코드로 작성하여 소스 코드와 함께 버전 관리가 가능함.
Groovy 언어와 Jenkins 파이프라인 문법을 알아야 함.
코드로 모든 것을 정의해야 하기 때문에, 간단한 작업도 상세한 설정이 필요할 수 있음.
Multibranch pipeline
여러 개의 브랜치에 대해 자동으로 CI/CD 파이프라인을 생성하고 실행할 수 있는 Jenkins의 item 유형.
Git과 같은 SCM 저장소의 브랜치를 자동으로 감지하고 개별적인 Pipeline을 실행하는 방식으로 동작.
적용 사례
대규모 프로젝트에서 브랜치별 CI/CD가 필요한 경우
SCM 기반으로 브랜치 변화를 감지하고 자동으로 파이프라인을 실행하는 경우
각 브랜치에서 독립적인 빌드/테스트 환경이 필요한 경우
작동 방식
SCM 연결: GitHub, GitLab, Bitbucket 등의 저장소를 Jenkins와 연결.
브랜치 감지: Jenkins가 SCM의 브랜치를 스캔하여
Jenkinsfile이 존재하는지 확인.파이프라인 자동 생성: 각 브랜치별로 독립적인 Pipeline이 자동으로 생성.
자동 실행: 새로운 브랜치가 푸시되거나 변경사항이 감지되면 해당 브랜치의 Pipeline 실행.
자동 정리: 브랜치가 삭제되면 해당 브랜치의 Pipeline도 자동으로 삭제됨.
유용한 사례
Git Flow를 사용하는 프로젝트:
develop,feature/*,hotfix/*등의 브랜치를 사용하여 협업하는 경우, 각 브랜치별로 CI/CD 테스트 및 배포를 진행 가능.여러 개발자가 개별 브랜치에서 개발하는 경우: 각 브랜치에서 독립적으로 테스트를 수행하고, 병합 전 문제가 없는지 확인 가능.
SCM의 브랜치 변경을 자동으로 반영하고 싶은 경우: Jenkins가 브랜치를 자동으로 감지하고 관리하기 때문에 수동으로 Job을 만들 필요 없음.
진행 중인 프로젝트에서는 개별 브랜치를 만들어서 사용하기도 하지만 최종적으로는 모두 main에 병합하고 있었기 때문에 Multibranch pipeline은 적합하지 않았다. Jenkins에서 webhook을 받기도 하고 파이프라인 내에서 다른 GitLab 소스를 통해 다른 파이프라인이 진행돼야 했기 때문에 freestyle이 아닌 pipeline으로 item을 선택했다.
간단한 배포 과정을 위한 빌드/배포용으로는 freestyle을 사용하기도 했다.
댓글 (0)
첫 댓글을 남겨 대화를 시작해 보세요.