AI 모델 구축 (3) RAG
AI 모델 구축 (3) RAG
Llama 3.1 모델에 파인튜닝을 적용하니까, 일반적인 질문도 파인튜닝 시 학습한 데이터로 답변을 해서 개선이 필요했다. 또한 정확도가 낮을 때가 있어서 답변 강화 목적으로 RAG를 만들었다. Llama 모델과 oss 모델 모두 RAG를 사용할 수 있도록 FE에서 특정 옵션이 켜질 경우 RAG 테이블을 참고하도록 구현했다.
<div className={`plus-menu ${showPlusMenu ? "" : "hidden"}`} ref={plusMenuRef}>
<button className="plus-item" onClick={handleAttach}>파일첨부</button>
<button
className="plus-item"
onClick={() => {
setXdworldMode((v) => !v);
setShowPlusMenu(false);
}}
>
{ragMode ? "RAG 해제" : "RAG 모드"}
</button>
</div>
</div>
{ragMode && (
<button className="mode-chip" onClick={() => setRagMode(false)}>
RAG ✕
</button>
)}
이런 식으로 프론트엔드에서 특정 모드를 받을 때는 RAG를 사용했고 백엔드는 RAG chat에 대한 서비스 계층을 새로 만들어서 구현했다.
전체 흐름 :
Spring에서 입력 받은 프롬프트를 임베딩 모델로 전달 → 임베딩 모델에서 벡터화
→ Spring에서 전달 받은 벡터 데이터를 구축한 vector DB에서 조회
→ Spring에서 조회된 데이터와 프롬프트를 AI 모델에 전달
임베딩 모델
임베딩 모델은 bge-m3 를 설치했다. bge-m3는 Ollama 서버에서 설치할 수 있고 REST API로 임베딩 처리가 가능하다는 장점이 있다.
임베딩 모델에 따라서 검색 정확도 자체가 달라진다고 한다. 모델 선택도 RAG 설계에 핵심 요소라고 볼 수 있다.
// 임베딩 모델 설치
ollama pull bge-m3
💡RAG 종류
pgvector + PostgreSQL
이미 Postgres 쓰고 있으면 운영 난이도 최소.
OLTP + Vector 검색 다 같이 할 수 있음.
Reddit 같은 대형 서비스도 선택 후보에 올리는 수준.
단, 대규모 고QPS + 대량 문서에서 extreme 튜닝은 필요.
Qdrant
Rust 기반, 퍼포먼스 최적화, HNSW 기반 ANN.
서버리스/클라우드 서비스도 제공,
JSON 스키마, payload 필터링 등 RAG용 기능 풍부.
Milvus
분산 아키텍처에 최적화된 vector DB.
자신들이 Reddit 사례, 클라우드 대규모 레퍼런스 등을 많이 내세움.
Weaviate
플러그인/모듈형, Graph-like 질의도 가능.
Hybrid search(BM25+벡터) 기능 내장.
고급 RAG
Hybrid Retrieval
BM25(키워드) + 벡터 검색 결과를 fusion (예: Reciprocal Rank Fusion)
법률/기술 문서처럼 키워드 정확도 중요 + 의미 검색도 필요한 곳에 효과적
Multi-Stage Re-ranking
1차: 빠른 ANN 검색(Top-50)
2차: Cross-encoder / LLM으로 상위 10개 재정렬
3차: LLM이 최종 컨텍스트 선택/요약
Contextual RAG / Graph-Augmented RAG
chunk 하나하나가 아니라,
문서 구조, 섹션 관계, 엔티티 그래프까지 이용해 multi-hop 질의를 처리
Agentic RAG
“질문 분석 에이전트”, “retrieval 에이전트”, “검증 에이전트” 등 여러 에이전트를 두고 협업시키는 방식
복잡한 분석/추론 시에도 강함
RAG 벡터 DB 설계
RAG는 pgvector 로 구성했다. 임베딩 모델은 bge-m3 모델은 1024차원을 제공한다. 사용하는 임베딩 모델마다 지원하는 차원이 달라, 설치한 모델에 따라 차원 수를 지정하면 된다.
데이터베이스는 AI 서비스에 사용하는 PostgresDB에 데이터베이스를 새로 만들었다. 테이블은 현재로써는 하나로 통합하고 추후에 도메인 분리가 필요하면 rag.chunk_code, rag.chunk_manual, … 이런식으로 나누는 것으로 정했다. 처음부터 나누면 백엔드 구현(검색 용도에 따라 쿼리 분리, 통합 검색 UNION ALL 등..)이 복잡해질 것 같아서 하나로 진행했다.
pgvector 확장자를 사용하려면 웹 검색 후 설치하고 DBMS 쿼리 콘솔에서 아래 명령어를 실행한다.
-- vector 확장 생
CREATE EXTENSION vector;
-- 목록 확인 (vector가 보이면 됨)
\\dx
-- 테이블 생성
CREATE TABLE rag_chunk (
id bigserial PRIMARY KEY,
-- 어떤 도메인/서비스에 속한 청크인지
domain text NOT NULL,
-- 한 도메인 내에서 문서/파일 ID
source_id text NOT NULL,
-- source_id 안에서 몇 번째 청크인지 (0,1,2,...)
chunk_no int NOT NULL,
-- 실제 검색/임베딩에 쓰이는 텍스트
content text NOT NULL,
-- 토큰 길이/길이 관리용 (선택)
token_count int,
-- 부가 정보 (project, file, function, url, title, tags, 등)
metadata jsonb,
-- 임베딩 벡터
embedding vector(1024) -- 임베딩 모델 차원에 맞게 수정
);
-- 인덱스 생성 (코사인 유사도 검색 기반)
-- 1) 벡터 검색 (필수)
CREATE INDEX rag_chunk_embedding_cosine_idx
ON rag_chunk
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- 2) source_id + chunk_id 조회용
CREATE INDEX rag_chunk_source_chunk_idx
ON rag_chunk (source_id, chunk_id);
-- 3) source_type 필터용
CREATE INDEX rag_chunk_metadata_source_type_idx
ON rag_chunk ((metadata->>'source_type'));
-- 4) project 필터용
CREATE INDEX rag_chunk_metadata_project_idx
ON rag_chunk ((metadata->>'project'));
테이블 생성 후 INSERT는 파이썬으로 임베딩 모델을 거쳐서 데이터를 적재했다.
결과
파인튜닝 + RAG 검색 결과가 나쁘지 않게 나왔다. 이전에는 파이썬이나 일반적인 오픈소스 기능을 알려줬다면, 현재는 학습한 내용 또는 RAG 기반으로 답변이 생성됐다. 하지만 디테일과 정확성이 떨어졌다.
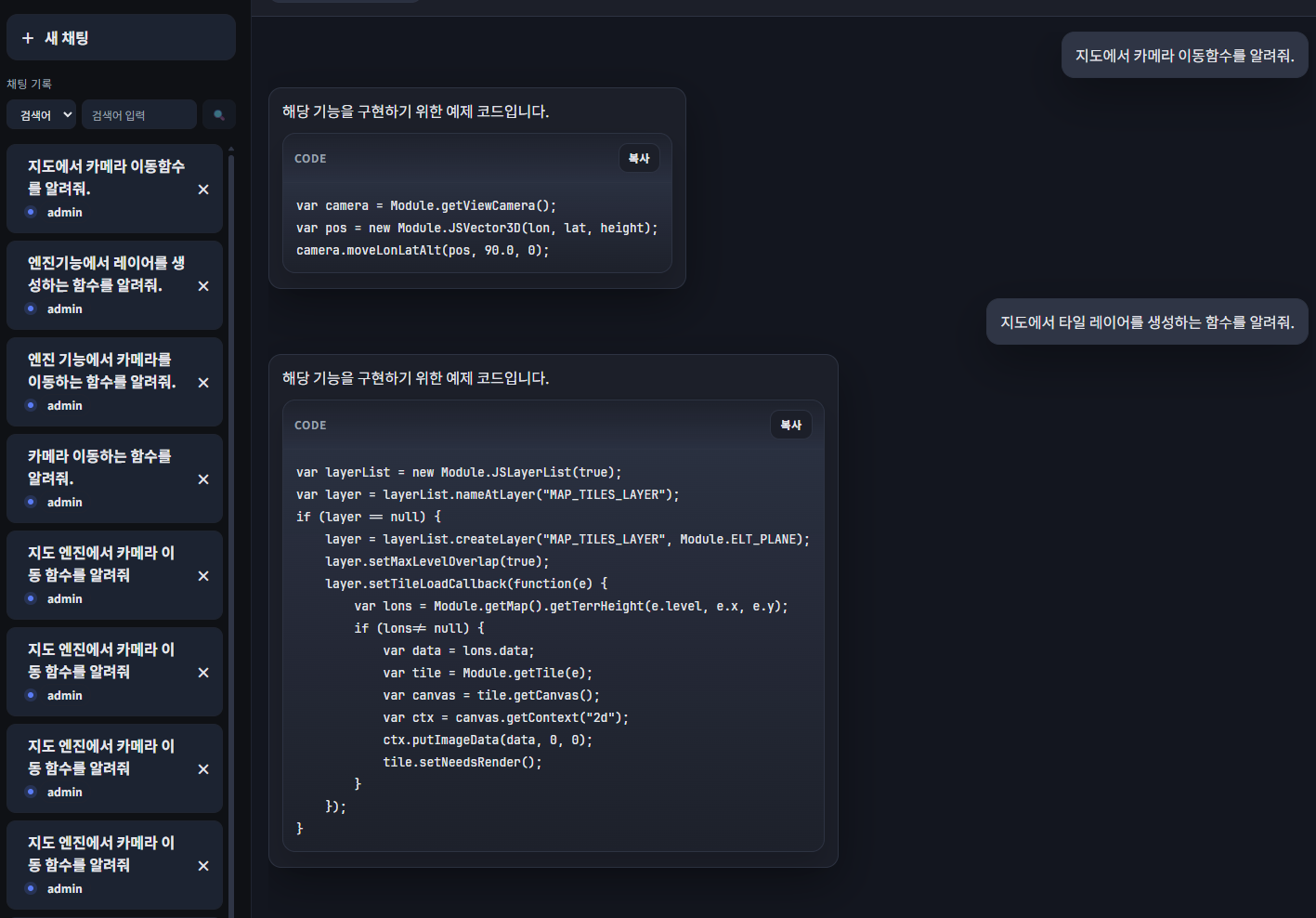
예를 들어서 간단한 대답은 잘 대답하는데, 코드가 길어지면 다른 기능의 함수와 혼용되어 사용되었다. 직접 사용해봤을 때의 평가는 이렇고, 데이터를 좀 더 다듬고 나면 2차 테스트 때 평가 및 모니터링도 진행해볼 예정이다.
검색 품질을 높이려면 단일 임베딩과 키워드 검색을 함께 사용한 하이브리드 검색을 많이 사용한다고 한다.
Dense Vector Search + Keyword(BM25) 검색
→ 의미 기반 + 문자열 기반 검색
이 부분도 좀 더 찾아보고 적용해보겠다.
댓글 (0)
첫 댓글을 남겨 대화를 시작해 보세요.