AI 모델 구축 (1)
AI 모델 선정, 아키텍처 구조
사내에서 사용할 수 있는 전용 AI 모델을 테스트로 진행해봤다. 주 용도는 회사 엔진 함수 검색 및 용도 분석용으로, WAS 서버와 모델을 연결해서 사내망에 호스팅 하는 것을 계획으로 잡았다.
테스트할 수 있는 GPU가 RTX 4060 8GB라 양자화된 AI 모델을 선택했다.
설치한 모델은 두 가지이다.
gpt-oss-20b Llama 3.1 8B
gpt-oss는 출시된지 얼마 되지 않았고, OpenAI에서 오랜만에 출시한거라 좋을거라 생각됐다. 또한 MoE(Mixture-of-Experts) 아키텍처를 채택해서 추론의 효율을 많이 올리고 VRAM 효율을 높여 현재 리소스에 적합하다고 판단했다. 4060 VRAM만으로는 양자화된 oss 구동이 힘들지만 통합 메모리가 여유가 있어 구동할 수 있었다.
💡 기존의 Dense(밀집) 모델은 어떤 질문이든 모든 파라미터가 동시에 작동한다. MoE는 질문에 따라 필요한 전문가 파라미터를 골라서 사용한다.
MoE 구성 MoE는 크게 두 부분으로 구성된다.
전문가(Experts) : 모델 내부의 작은 서브 네트워크들이다.
라우터(Router/Gating Network) : 들어온 질문(토큰)을 보고 어떤 전문가가 가장 질문을 잘
해결할지 판단하고 전달한다.
이를 통해 효율적인 추론이 가능해진다. 단점은 모든 메모리를 올려야 하기 때문에 경량화된 다른
AI모델에 비해 RAM이 많이 필요하다는 것이다.
Llama를 만든 메타는 그래도 최근까지는 오픈소스 체제를 유지해왔고, 속도가 빨라서 선택했다.
oss는 VRAM의 용량 때문에 추론용으로만 사용하고 Llama는 QLoRA를 진행해볼 계획이라 좀 더
가벼운 모델이 필요했다.
우선 테스트는 Ollama 서버를 기본으로 진행했다. Llama는 fastAPI 서버에 올리고 Docker
이미지로 배포했다. RAG도 구성할 예정이라 Ollama 서버에 임베딩 모델을 설치하고 임베딩을
하도록 구성했다.
테스트 후 전체 아키텍처는 아래와 같이 설계했다.
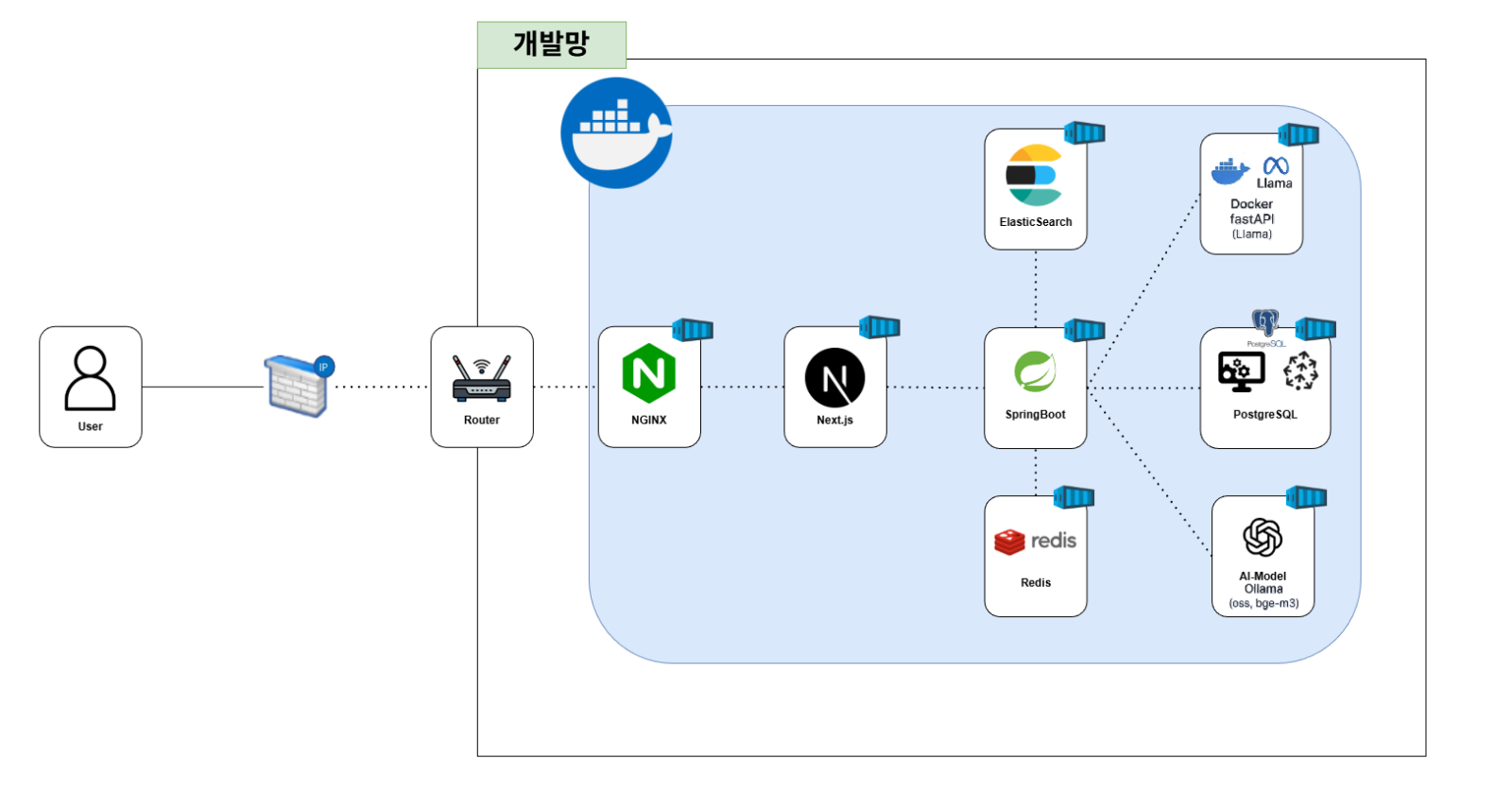
BE로 WebFlux를 고려해봤는데, 트래픽이 많지 않을 것 같아서 Spring Boot로 진행했다. 나중에 필요하면 JDK 21 가상 스레드로 커버하면 되지 않을까.
1. 모델 설치하기
모델 설치 전체 과정
NVIDIA 드라이버 최신으로 맞추기
Ollama 설치
gpt-oss-20b 모델 다운로드
HTTP API 호출 테스트
웹 서비스와 연동
a. NVIDIA 드라이버 상태 확인
RTX 4060을 사용하고 있기 때문에 별도의 CUDA Toolkit 없이 드라이버만 있으면 Ollama가
GPU를 사용한다. GeForce Experience 또는 NVIDIA 앱에서 드라이버를 업데이트 하면 된다.
설정 후 재부팅 진행 → 모델 구동 시 GPU 리소스 사용량을 확인하면 열심히 돌아가는 것을
확인할 수 있다.
b. Ollama 설치
브라우저에 Ollama 검색 → 홈페이지 접속 후 다운로드 하면 된다.
설치 후 자동으로 실행되며 cmd, PowerShell, Windows Terminal에서 ollama 명령어를 바로 사용할 수 있다.
구동 시 기본 포트 localhost:11434로 구동되며, REST API를 제공한다.
c. gpt-oss-20b 모델 설치 및 실행
// 모델 실행(자동 다운로드) 명령어
ollama run gpt-oss:20b이렇게 실행하고 나면 터미널 창에 프롬프트가 생기고, AI와 이 프롬프트를 통해 대화를 주고 받을 수 있다.
간단한 질문을 던진 후 GPU 리소스를 확인을 통해 GPU 사용 여부를 확인해봐야 한다.
Ollama에서 자동으로 11434 포트로 서버를 올려주기 때문에 BE 서버에서 요청을 보내면 AI의 응답을 받을 수 있다.
예시)
// FE 예시
export async function askLocalOllama(messages: { role: string; content: string }[]) {
const res = await fetch('<http://localhost:11434/api/chat>', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: 'gpt-oss:20b',
messages,
stream: false,
}),
});
if (!res.ok) throw new Error('Ollama error: ' + res.status);
const data = await res.json();
return data.message?.content ?? '';
}
// BE 예시
WebClient client = WebClient.builder()
.baseUrl("<http://localhost:11434>")
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.build();
public Mono<String> askOllama(String userPrompt) {
Map<String, Object> body = Map.of(
"model", "gpt-oss:20b",
"messages", List.of(
Map.of("role", "user", "content", userPrompt)
),
"stream", false
);
return client.post()
.uri("/api/chat")
.bodyValue(body)
.retrieve()
.bodyToMono(Map.class)
.map(res -> {
// 응답 구조는 Ollama docs 기준
Map message = (Map) res.get("message");
return (String) message.get("content");
});
}
백엔드 서버가 필요없으면 예시처럼 FE에서 바로 호출해도 된다. 현재 구축하고자 하는 서비스에 세션, 권한, 관리 기능도 필요했기 때문에 백엔드를 구축하고 모델 호출은 항상 백엔드에서 진행하도록 만들었다.
Ollama의 이점
Ollama는 AI 모델을 사용하기 쉽도록 다양한 기능을 제공한다.
모델 다운로드/관리
원하는 오픈소스 모델 다운로드.
로컬에 캐시되어 이후에는 바로 실행됨.
런타임(추론 엔진)
내부적으로 llama.cpp 스타일 엔진을 활용한다.
GPU + CPU를 적절하게 사용하여 연산을 수행.
4bit/5bit 양자화 모델도 읽어서 실행.
토큰화, attention, 샘플링, kv-cache 관리 등 LLM 추론에 필요한 저수준 작업을 모두 처리.
서버 역할(HTTP API)
설치 시
http://localhost:11434에 HTTP 서버를 띄움./api/chat, /api/generate, /api/embeddings 등 REST 엔드포인트 제공.
스트리밍 및 세션 관리
API 요청 시
stream : true옵션을 주면, 답변을 토큰 단위로 바로바로 답을 수 있다. (ChatGPT, Gemini 사용 시 답변이 한 번에 오는 게 아니라 나눠서 오는 것처럼)여러 요청이 들어와도 내부적으로 큐 처리/스레드 관리 등을 해줌.
요청이 몰리면 분산 처리를 해야 돼서 BE에서 Queue를 통해 순차 처리하도록 구현하면서 Ollama 서버에서 순차처리를 해줄 수 있지 않을까 하고 찾아보니까 실제로 기능을 제공하고 있었다. Ollama 자체에서 AI모델을 서비스할거면 요청이 몰렸을 때 걱정을 하지 않아도 돼서 좋은 것 같다.
댓글 (0)
첫 댓글을 남겨 대화를 시작해 보세요.